1:
Initialize 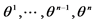 arbitrarily
arbitrarily
2:
for episode = 1, M do
3:
Initialize s
4:
Repeat
5:
Choose 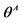 where
where 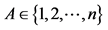 using probability
using probability 
6:
Choose a from s using policy derived from 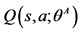 (e.g., ε-greedy)
(e.g., ε-greedy)
7:
Take action a, observe 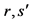
8:
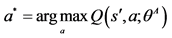
9:
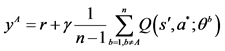
10
Train network using 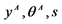
11:
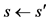
12:
until
13:
end for