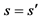Initialize Q values
Repeat t times (t = number of learning episodes)
Select a random state s
Repeat until the end of the learning episode
Select an action a
Receive an immediate reward r
Observe the next state 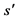
Update the Q table according to the update rule
Set