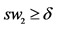// P is an n × n predicate similarity matrix, n is the number of predicates in ontologies
// δ is the threshold of silhouette width ![]()
Input: P, δ
// a hierarchy with a set of clusters ![]() the jth cluster at ith level
the jth cluster at ith level
Output:![]()
1. i=1
2. repeat
3. // n is the number of input predicates, m is the number of predicates of cluster j at level i,
4. // optimal k (![]() ) from m predicates of the cluster at level i (
) from m predicates of the cluster at level i (![]() ) using
) using ![]() function
function
5. ![]() //compute Neighborhood silhouette width
//compute Neighborhood silhouette width
6. k = Optimal K(![]() ) //fine the optimal k based on
) //fine the optimal k based on ![]()
7. ![]()
8. If (k > 1) then
9. 
10. for j = 1 to k
11. 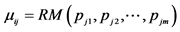 (// random mean for predicates in
(// random mean for predicates in 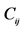 (cluster j at level i)
(cluster j at level i)
12. end
13. for each 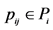 do
do
14.  //wij is the degree, m is the fuzzifier
//wij is the degree, m is the fuzzifier
15. end
16. 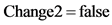
17. sw = 0
18. repeat
19. for each 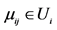 do
do
20. Update Cluster(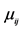 )
)
21. end
22. for each 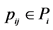 do
do
23. 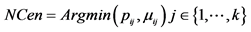
24. if 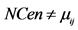 then
then
25. 
26. 
27. 
28. end if
29. 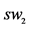 = Silhouette Width (
= Silhouette Width (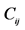 ) //computesil houette width
) //computesil houette width
30. while 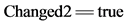
31. while 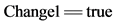 and
and